python
目录
今天写一下我对正则表达式元字符的理解,和一些匹配例子把,
元字符我的理解是正则查找条件代码的字符
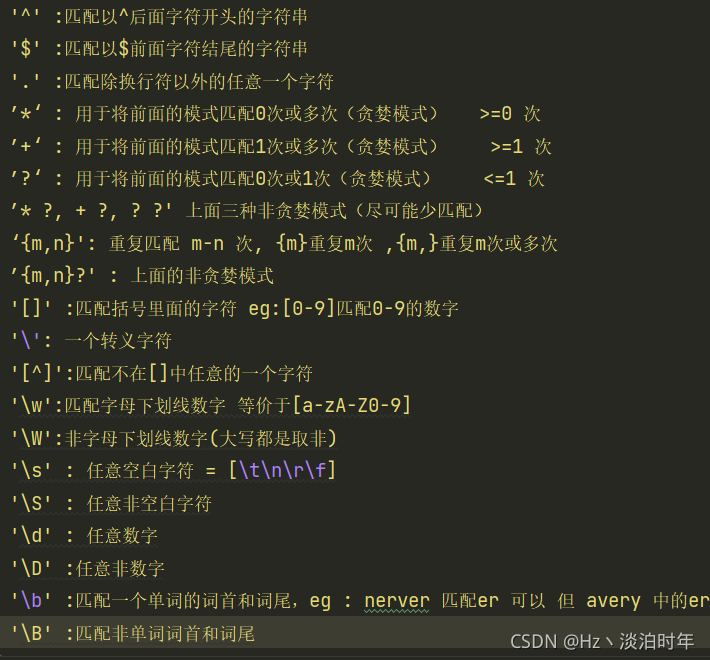
以上差不多是会使用的一些基本的元字符匹配,下面简单运用几个说明一下
三丶元字符的使用和一些注意事项
A:简单使用
import re msg = 'A2bdhsg22sg2134dk555K2lk7ds5zjfl' result = re.findall('[a-zA-Z][0-9][a-zA-Z]',msg) print(result)#['A2b', 'K2l', 'k7d', 's5z'] '''当然也可以这样写''' result = re.findall(r'[A-Za-z]\d[a-zA-Z]',msg) print(result)#['A2b', 'K2l', 'k7d', 's5z'] # 如果中间有多位数字 a55h a46465h # 可以使用 + 至少出现一次 或者多次 result = re.findall(r'[A-Za-z]\d+[a-zA-Z]',msg) print(result)#['A2b', 'g22s', 'g2134d', 'k555K', 'k7d', 's5z'] 注意 :转移字符\d 所有我们前面加个r 或者写\\ 都能完成匹配 # 后是结果
B:整体匹配
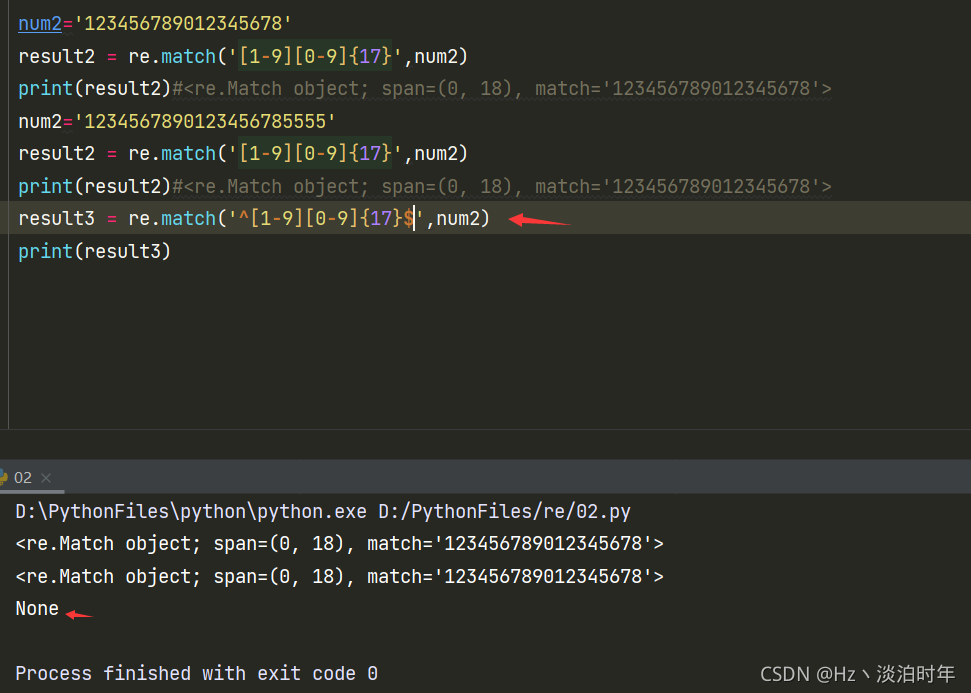
举一个简单的例子 我们要匹配一个身份证号18位数不含x, 身份证开头不能为0
num2='123456789012345678' result2 = re.match('[1-9][0-9]{17}',num2) print(result2)#<re.Match object; span=(0, 18), match='123456789012345678'> num2='1234567890123456785555' result2 = re.match('[1-9][0-9]{17}',num2) print(result2)#<re.Match object; span=(0, 18), match='123456789012345678'>发现超过位数18位为我们还是可以成功匹配到,所以我们需要对整体进行匹配 加入元字符‘$' 和'^'
进行匹配
C: | 与 [] 选择
现在我们需要判断他是否唯一个合法的电子邮箱(126.qq.163)地址 该如何写出正则表达式:邮箱的格式应该是 xxxx@xx.xx.com eg: 24775366510@qq.com 24775366510@163.com 不能以数字0开头 前面数字5-12位:
email1 = '2477723@qq.com' email2 = '2477723@126.com' email3 = '24775dsjal23@163.com' result1 = re.match(r'[1-9]\d{4,11}@(qq|126|163)\.com',email1) result2 = re.match(r'[1-9]\d{4,11}@(qq|126|163)\.com',email2) result3 = re.match(r'[1-9]\d{4,11}@(qq|126|163)\.com',email3) print(result1)#<re.Match object; span=(0, 14), match='2477723@qq.com'> print(result2)#<re.Match object; span=(0, 15), match='2477723@126.com'> print(result3)#None| 元字符是选择字符串进行 而 [] 是选择单个字符进行匹配
D: ()分组
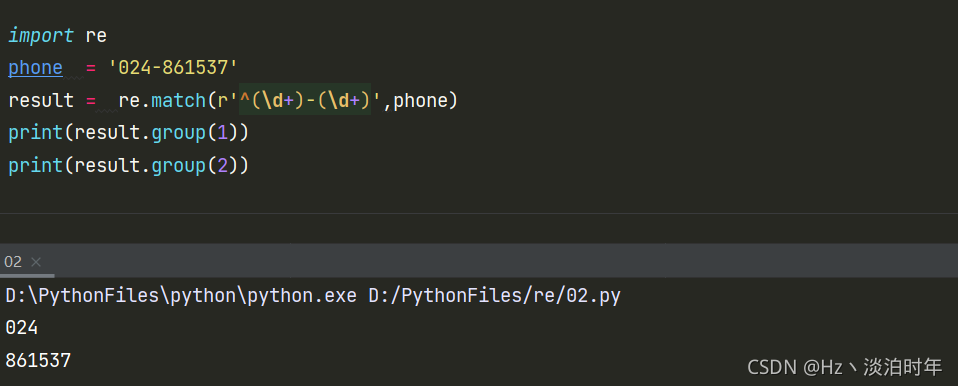
最后一个问题说一下分组 前面已经说过可以通过group 获取内容,现在讲一下分组,国际电话 xxx-xxxx形式,我们可以通过分组的形式分别获取前面的国家编号和电话内容
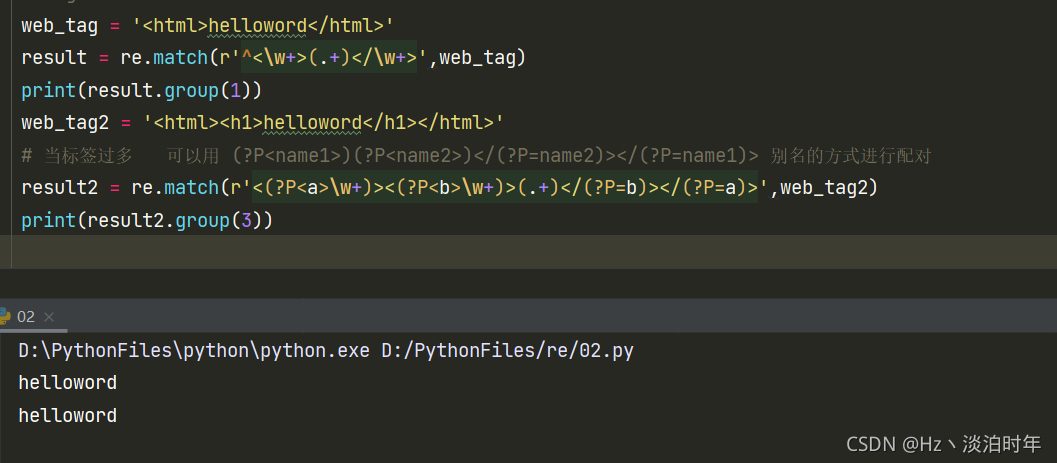
分组常用对网页标签的获取
ok 正则表达式大概我就介绍完了,贪婪匹配先欠着 ,下次写python 数据分析numpy 库的使用了 我刚学希望一起学习, 如果可以一起监督学习的话,可以私聊我一起哈哈哈虽然我很懒的 这大概是我学习的方向 明天写个学习计划
